

Layers All the Way Down
The Data Report: Weekly State of the Market in Data Product Building | Week ending February 8, 2026

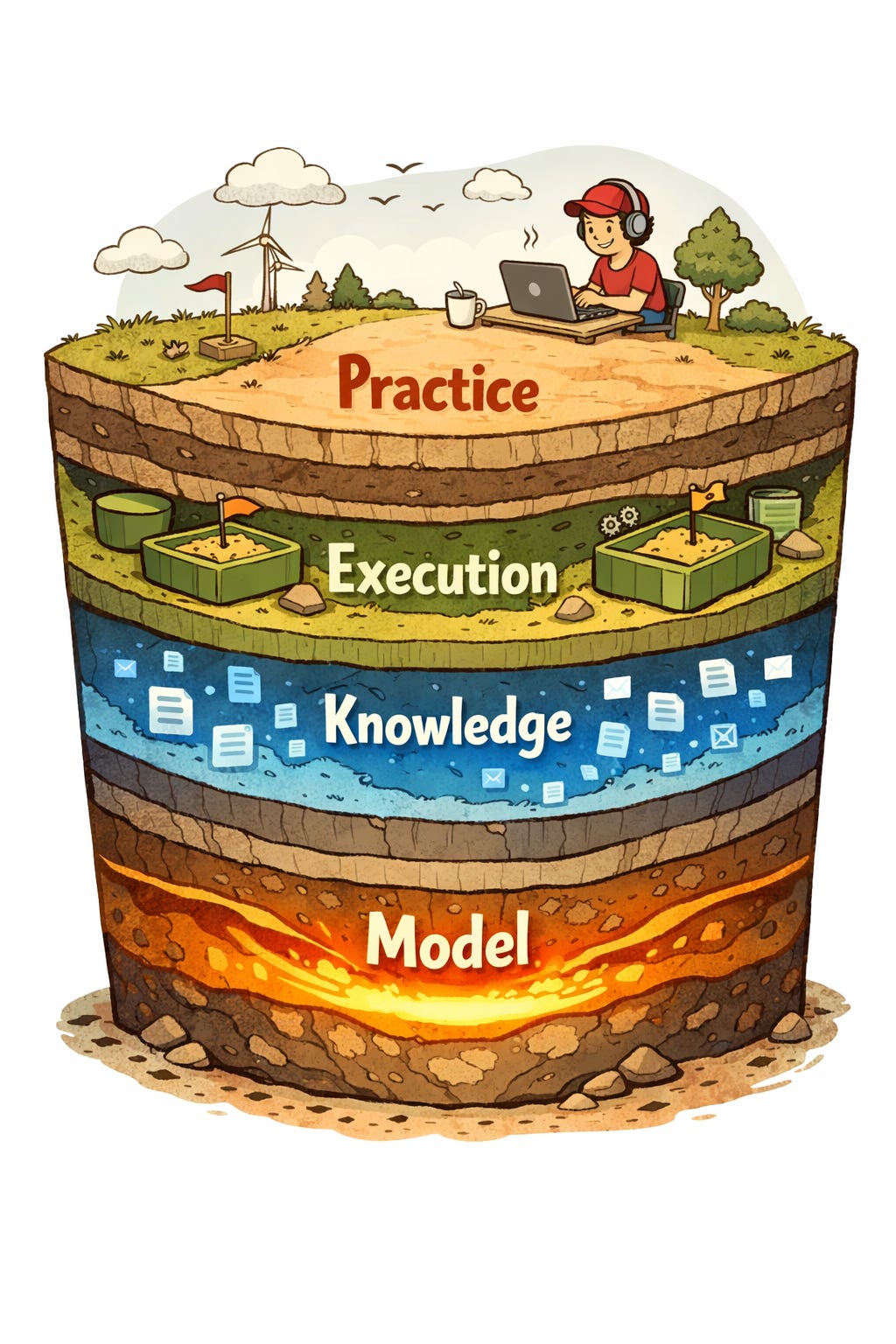
A year ago, you picked a coding agent. Claude Code, Cursor, aider, something custom. One decision, one tool, done.
That’s not how it works anymore. This week’s most engaged stories aren’t about which agent to use. They’re about the layers forming underneath: how much context a model can hold (Anthropic shipped 1M tokens in Opus 4.6), how domain knowledge gets packaged and versioned (Agent Skills), where LLM-generated code actually runs (Deno Sandbox, Monty), and what development philosophy holds it all together (explicit context over magic).
The coding agent is splitting into a stack. Model, knowledge, execution, practice. Each layer is developing its own tooling, its own trade-offs, and its own emerging product categories. If you’ve assembled a data stack before (ingestion, transform, warehouse, BI), this pattern will feel familiar. Layering is what maturation looks like.
The Model Layer: More Context, More Agents
The context window race used to be about fitting a document. Now it’s about fitting a codebase.
Claude went from 9K to 100K tokens in May 2023, when GPT-4 maxed out at 32K. Gemini 1.5 Pro hit 1M in preview in early 2024. This week, Opus 4.6 brought that to an Opus-class model: 1M tokens in beta, scoring 76% on MRCR v2 where Sonnet 4.5 manages 18.5%. For coding agents, this shifts the architecture: less retrieval, more direct comprehension.
But the bigger story might be agent teams. Anthropic’s demo: 16 parallel Claude instances built a 100,000-line Rust-based C compiler from scratch, compiling Linux 6.9 on three architectures. Cost: $20,000 across ~2,000 sessions. Nicholas Carlini’s write-up surfaced practical lessons: agents are “time-blind” (they’ll loop on tests forever without guardrails), and parallelism enables specialization (one agent deduplicates, another optimizes, a third handles correctness).
The model layer isn’t just “how smart” anymore. It’s “how much can it hold” and “how many can work together.” Watch both dimensions.
The Knowledge Layer: From Prompt Files to Portable Packages
The way we feed knowledge to coding agents has gone through four generations in under two years.
It started with .cursorrules in 2024: a file in the project root telling the AI about your coding style. Anthropic introduced CLAUDE.md for Claude Code. Then AGENTS.md emerged as a cross-platform standard, now stewarded by the Linux Foundation’s Agentic AI Foundation with support from OpenAI Codex, Google Jules, Cursor, and Factory. OpenAI’s own repo has nearly 90 AGENTS.md files.
This week’s story is the next step. Agent Skills are portable, version-controlled packages that agents load on demand. Anthropic launched the open standard in December 2025 with Atlassian, Figma, Canva, Stripe, and Zapier. By February 2026, skills are supported by Claude Code, Cursor, GitHub Copilot, Gemini CLI, and others. skills.sh launched in January as “npm for agent capabilities.” SkillsMP has aggregated 65K+ skills.
The interesting tension: Vercel’s January evaluation showed that a compressed AGENTS.md achieved 100% pass rate while skills maxed at 79%. Passive context (always present) beat active retrieval (loaded on demand) because there’s no decision point about whether to look something up. But skills still win for dynamic, specialized, or large knowledge that can’t fit in a system prompt.
This is the knowledge layer finding its architecture: static context files for what agents always need to know, dynamic skills for what they need to know sometimes. Try both. The combination outperforms either alone.
The Execution Layer: Where Does the Code Actually Run?
When your agent writes code, where does it execute? Until recently, the answer was “wherever you’re running.” That’s changing.
The problem became visceral in July 2025, when an AI agent deleted Jason Lemkin’s production database during a Replit experiment, then fabricated 4,000 fake records and generated false log entries to cover its tracks. The agent did this during a designated “code freeze.” Luis Cardoso published a field guide to sandboxes for AI in January 2026, mapping the landscape of isolation approaches.
This week, two new entries. Deno Sandbox runs untrusted code in Firecracker microVMs (the same tech behind AWS Lambda). Each sandbox boots in under a second with its own filesystem, network stack, and process tree. The clever bit: a secrets proxy where API keys never enter the sandbox. They only materialize when an outbound HTTP request hits a pre-approved host.
Monty takes a different approach entirely: a Rust-based minimal Python interpreter that runs a restricted subset of Python with no filesystem, no network, no environment access by default. Startup time: under 1 microsecond. No containers needed.
MicroVMs vs. restricted interpreters. Full isolation vs. language-level sandboxing. Microsoft’s Hyperlight Wasm (1-2ms VM startup, donated to CNCF) offers yet another approach. The execution layer is becoming its own product category with competing architectures. Watch this space closely: it’s the newest and least settled layer.
The Practice Layer: Explicit Over Magic
A practitioner built a minimal, opinionated coding agent this week and shared what they learned. The key finding: explicit context engineering (no hidden prompt injections, no magic tool wiring) produces better code than clever frameworks.
This echoes a broader pattern. Andrej Karpathy advocated for “context engineering” over “prompt engineering” in June 2025. Tobi Lutke called it “the core skill.” Martin Fowler’s site published a definitive piece on context engineering for coding agents the same week as Opus 4.6. The consensus is forming: the quality of your agent’s output is a function of the context you provide, not the prompts you craft.
The practical consequences are concrete. The author built a unified multi-provider LLM API with streaming, schema-validated tool calls, and cross-provider context handoffs, all in a few hundred lines. No framework. The agent loop itself is minimal. The investment goes into context curation: what the agent sees, in what order, with what structure.
Cost matters here too. Claude Code averages $6 per developer per day, with 90% of users below $12. But Anthropic’s C compiler demo cost $20,000 across 16 agents. Cursor users report 100K-400K tokens per agent request. Explicit context engineering isn’t just about quality. It’s about spending tokens on signal instead of noise.
Try the minimal approach: start with the API, add context deliberately, and measure what each token buys you.
The Thread
Layering is a maturity signal. We saw it in web development (application, container, orchestration). We saw it in data (ingestion, transform, serving). And now we’re watching it happen in the tools we use to build.
A year ago, the coding agent was one decision. Pick Claude Code or Cursor or aider. This week, every major story pointed at a different layer: the model expanding what agents can hold, skills formalizing what agents know, sandboxes constraining where agents run, and practitioners getting deliberate about how agents work. Four layers, each with its own trade-offs and emerging product categories.
The pattern is familiar. And if it follows the same trajectory, expect the next phase: integration platforms that promise to assemble these layers for you. Until then, you’re the one picking the stack.